
Imagine walking through a bustling marketplace, overwhelmed by the sights, sounds, and smells. You want to find the perfect spice for your dish, but the sheer variety seems impossible to navigate. This is the challenge many researchers face – dealing with data sets bursting with dimensions, each representing a different facet of the problem. However, just as a good spice merchant can guide you to the right blend, there are powerful techniques like Independent Component Analysis (ICA) and Principal Component Analysis (PCA) that can help us extract meaning from complex data landscapes.

Image: allthedifferences.com
Both ICA and PCA belong to a family of techniques known as dimensionality reduction, which essentially means simplifying data by reducing the number of variables while preserving as much information as possible. But how do these techniques achieve this simplification, and how do they differ? This article dives deep into the world of ICA and PCA, unraveling their intricacies and empowering you to choose the right tool for your data exploration journey.
The Core Concepts: A Gentle Introduction to PCA and ICA
Before we delve into the complexities, let’s grasp the underlying principles of these two techniques. Imagine a cloud of points in multi-dimensional space. PCA, like a skilled photographer, seeks the best angles to capture the essence of this cloud. It identifies the directions of greatest variance, finding the principal components (axes) that capture the most information about the data. Essentially, PCA seeks to find a new, smaller set of variables (the principal components) that are uncorrelated and explain the largest amount of variability in the original dataset.
ICA, on the other hand, takes a more exploratory approach, focusing on underlying sources that contributed to the observed data. Imagine multiple independent audio sources playing simultaneously – a conversation, a radio program, and music. ICA aims to decompose the mixed signal, isolating the individual sources, effectively separating the signal in the “cocktail party problem.” It searches for statistically independent components that, when mixed together, reproduce the original data. In essence, ICA seeks to find a new set of variables (the independent components) that are statistically independent from one another.
PCA: The Maestro of Variance
PCA, often described as a “linear transformation,” works by performing a rotation and scaling operation on the data. This transformation allows us to identify the most significant axes of variation within the data, essentially exposing the underlying structure.
Imagine a collection of facial images. PCA can analyze these images and identify the principal components representing the variations in facial expressions, such as eye movements, mouth shapes, and eyebrow positions. This allows us to represent each face with a reduced set of numbers representing its expression variation along those key axes.
Applications of PCA:
- Image Compression: By focusing on the most significant principal components, PCA can significantly reduce the data size required to store images without compromising visual quality. This is crucial for efficient image storage and transmission.
- Feature Extraction: By identifying relevant features through PCA, we can create more efficient models for machine learning tasks like image recognition, where dimensionality reduction is critical.
- Data Analysis & Visualization: PCA can help us visualize high-dimensional data on a lower-dimensional space, facilitating pattern identification and understanding complex relationships.
ICA: The Source Hunter
ICA, in contrast to PCA, focuses on finding independent sources that contribute to the observed signals. It operates on the assumption that the observed data is a linear combination of these independent sources.
Think of a recording of a cocktail party, where the microphone captures several simultaneous conversations. ICA acts like a forensic scientist, separating the distinct voices and melodies, revealing the independent sources that contributed to the mixed audio signal.
Applications of ICA:
- Medical Imaging: ICA helps separate brain signals from artifacts in fMRI data, providing clearer insights into brain activity. It can also be used to isolate different sources of brain activity, such as those related to speech and movement.
- Speech Recognition: ICA helps identify individual speakers in a noisy environment, providing enhanced accuracy for speech recognition systems. It can also separate various vocalizations in animal communication studies.
- Financial Analysis: ICA can help identify independent factors that influence stock prices, leading to more accurate predictions of market fluctuations. It can also help uncover hidden relationships within complex financial datasets.
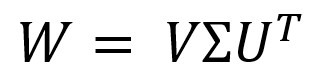
Image: techwithtech.com
Choosing the Right Tool: A Decision Making Framework
Both PCA and ICA are powerful techniques for dimensionality reduction, but their applications and effectiveness vary based on the specific problem and data structure.
Consider using PCA when:
- You need to find the axes of greatest variance in your data.
- You want a simple and efficient way to reduce the dimensionality of your data.
- You are working with data that exhibits linear relationships.
Consider using ICA when:
- You suspect your data is a mixture of independent sources.
- You want to identify and separate the underlying sources that contribute to your data.
- You are working with data that may exhibit non-linear relationships.
Beyond the Basics: Emerging Trends in ICA and PCA
The field of dimensionality reduction is constantly evolving, and both ICA and PCA are being refined and integrated into new applications. One such development is the emergence of non-linear PCA techniques, which can handle data with more complex relationships than traditional linear PCA.
Kernel PCA, for instance, uses a non-linear transformation to project data into a higher-dimensional space where it can be analyzed linearly before being projected back into a reduced-dimensional space. This allows it to capture non-linear structures that traditional PCA might miss.
Similarly, non-linear ICA techniques are being explored to address the limitations of traditional ICA, which assumes linear mixing of independent sources. These techniques often involve the use of non-linear functions to achieve more accurate source separation.
Expert Insights and Actionable Tips
“When faced with a high-dimensional dataset, don’t rush to apply PCA or ICA blindly,” says Dr. Sarah Johnson, a renowned data scientist. “First, understand your data and the problem you’re trying to solve. Are you looking for underlying sources, or simply for the axes of greatest variation? The choice of technique should flow naturally from your goals.”
“Don’t forget, these are powerful tools, but they are not magic bullets,” adds Dr. David Lee, a leading researcher in dimensionality reduction. “Always validate your results, explore different methods, and never lose sight of the underlying context of your data.”
Ica Vs Pca
Conclusion
PCA and ICA, while similar in their goals, offer distinct approaches to navigating the world of high-dimensional data. By understanding their strengths and weaknesses, researchers can choose the right tool for effective data analysis and interpretation. Both techniques, with their continuous advancements, remain essential tools for uncovering hidden patterns and simplifying complex datasets in various disciplines, from image recognition to financial analysis. So, the next time you’re faced with a data deluge, remember these powerful techniques for navigating the intricate world of dimensionality reduction. You might just discover hidden gems within the chaos, leading you to new insights and groundbreaking discoveries.
:max_bytes(150000):strip_icc()/OrangeGloEverydayHardwoodFloorCleaner22oz-5a95a4dd04d1cf0037cbd59c.jpeg?w=740&resize=740,414&ssl=1 "What to Use for Laminate Floor Cleaner – A Comprehensive Guide")





